연구용 AI 워크스테이션 구입기준: Mac Studio, DGX Spark, Ryzen AI Max+ 395

앞선 글에서 애플 가격 인상을 [[기기 주권]]의 문제로 읽었다. 그런데 문제는 여기서 끝나지 않는다. 연구를 계속하려면 결국 장비를 사야 한다. 특히 [[로컬 파인튜닝]]을 하고 싶다면 질문은 더 구체적이다.
Mac Studio를 살 것인가, NVIDIA DGX Spark 계열로 갈 것인가, 아니면 AMD Ryzen AI Max+ 395 계열을 기다릴 것인가.
이 글은 “가장 센 장비가 무엇인가”를 고르는 글이 아니다. 연구용 장비는 벤치마크 1등보다 중요하게 봐야 할 것이 있다. 내가 실제로 돌릴 실험, 실패했을 때 다시 돌릴 수 있는 환경, 논문·오픈소스 코드 재현성, 데이터 보안, 그리고 예산이다. 특히 파인튜닝은 한 번 실행해서 끝나는 일이 아니라, 데이터셋을 바꾸고, LoRA rank를 바꾸고, batch size를 줄였다 늘리고, 여러 번 실패하면서 감을 잡는 일이다.
그래서 결론부터 말하면 이렇다.
논문·오픈소스 재현성과 CUDA 호환성이 최우선이면 DGX Spark, 큰 통합 메모리와 조용한 개인 연구실 장비가 필요하면 Mac Studio, 예산 대비 로컬 실험량이 중요하면 Ryzen AI Max+ 395 계열이다.
1. 비교 대상
이번 비교는 세 제품군이다.
-
Apple Mac Studio 2025
- M4 Max 또는 M3 Ultra
- 최대 128GB 또는 256GB 통합 메모리
- [[MLX]] 기반 Apple Silicon 워크플로우
-
NVIDIA DGX Spark / GB10 Grace Blackwell 계열
- 128GB coherent unified memory
- Blackwell Tensor Core, FP4
- [[CUDA]]·PyTorch·LLaMA Factory 중심
-
AMD Ryzen AI Max+ 395 계열
- Framework Desktop, 미니 PC, 워크스테이션 형태
- 128GB LPDDR5x, Radeon 8060S
- Linux/Windows, [[ROCm]]·llama.cpp 중심

2. 핵심 스펙 비교
| 구분 | Mac Studio | NVIDIA DGX Spark | Ryzen AI Max+ 395 계열 |
|---|---|---|---|
| 대표 칩 | M4 Max / M3 Ultra | GB10 Grace Blackwell | AMD Ryzen AI Max+ 395 |
| CPU | 최대 32코어(M3 Ultra) | 20코어 Arm | 16코어 Zen 5 / 32스레드 |
| GPU/가속기 | Apple GPU 최대 80코어 | Blackwell GPU, 5세대 Tensor Core | Radeon 8060S, 40 CU |
| 메모리 | M4 Max 최대 128GB, M3 Ultra 최대 256GB | 128GB unified memory | 최대 128GB LPDDR5x |
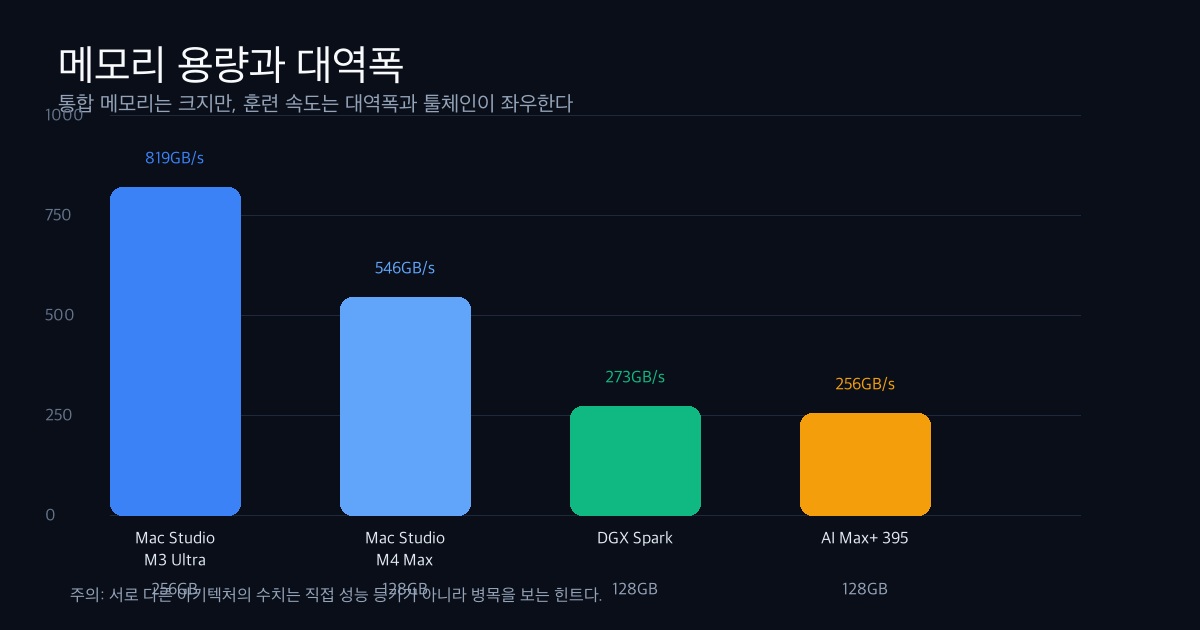
| 메모리 대역폭 | M4 Max 최대 546GB/s, M3 Ultra 819GB/s | 273GB/s | 약 256GB/s |
| 대표 툴체인 | MLX, mlx-lm, llama.cpp-metal | CUDA, PyTorch, TRT-LLM, LLaMA Factory | ROCm, llama.cpp, LM Studio, Linux/Windows |
| 공식/공개 가격 단서 | M4 Max 시작 $1,999, M3 Ultra 시작 $3,999 | NVIDIA Marketplace $4,699 | Framework 128GB 구성/보드 기준 약 $1,999~$3,149 범위 |
| 컴퓨존 국내 구매 단서 | Mac Studio 상품은 확인되나 기업회원/CTO 특별가로 공개가 미노출 | Dell Pro Max GB10 128GB/4TB/AS 3Y 약 935만 원, HP ZGX Nano G1N 128GB/4TB 혜택가 약 912.5만 원 | HP Z2 Mini G1a AI Max+ 395 128GB/1TB 약 455만 원(품절), 128GB/2TB 약 642.7만 원, 128GB/4TB 약 729.5만 원 |
| 가장 큰 장점 | 큰 통합 메모리, 저소음, macOS 생산성 | CUDA 재현성, NVIDIA 소프트웨어 스택 | 가격 대비 128GB, PC 생태계, Linux 유연성 |
| 가장 큰 약점 | CUDA 없음, PyTorch/MPS 한계 | 가격, 128GB 고정, ARM64 변수 | ROCm/드라이버/튜닝 변수 |
수치만 보면 Mac Studio M3 Ultra의 메모리 대역폭이 돋보인다. Apple 공식 스펙 기준 M3 Ultra는 819GB/s, M4 Max 상위 구성은 546GB/s다.1 DGX Spark는 128GB LPDDR5x unified memory와 273GB/s 대역폭을 갖는다.2 AMD Ryzen AI Max+ 395는 128GB LPDDR5x-8000, 256-bit 메모리 구조와 Radeon 8060S 그래픽을 제공한다.3
국내 실구매 관점에서는 컴퓨존 기준 가격도 같이 봐야 한다. 2026년 7월 2일 확인 시점 기준으로 DGX Spark 기반 Dell Pro Max GB10 128GB/4TB/AS 3Y는 약 935만 원, HP ZGX Nano G1N 128GB/4TB는 혜택가 약 912.5만 원이었다.45 Ryzen AI Max+ 395 계열 HP Z2 Mini G1a는 128GB/1TB 기본상품이 약 455만 원으로 표시됐지만 품절 상태였고, 128GB/2TB 구성은 약 642.7만 원, 128GB/4TB 구성은 약 729.5만 원 수준으로 확인됐다.65 Mac Studio는 컴퓨존에 M4 Max와 M3 Ultra 상품이 등록되어 있으나, 기업회원/CTO 특별가 또는 문의형 구조라 공개 가격을 단순 비교하기 어렵다.7
하지만 파인튜닝 장비는 대역폭만 보고 고르면 안 된다. 어떤 코드가 가장 덜 고장나는가가 중요하다.
3. 파인튜닝에서 실제로 중요한 것
[[파인튜닝]] 관점에서 보면 구매 기준은 네 가지다.
| 기준 | 왜 중요한가 |
|---|---|
| 메모리 용량 | 모델, optimizer state, activation, batch, context length가 모두 메모리를 먹는다 |
| 툴체인 성숙도 | CUDA 예제는 많고, MLX/ROCm 예제는 상대적으로 적다 |
| 실험 반복 비용 | 한 번의 성공보다 여러 번의 실패를 감당해야 한다 |
| 연구 재현성 | 논문·GitHub 코드가 어느 환경을 전제로 쓰였는가 |
여기서 많은 사람이 헷갈리는 지점이 있다. 큰 모델을 로컬에서 “실행”하는 것과 “파인튜닝”하는 것은 다르다. 70B 모델을 양자화해서 추론하는 것과, 같은 모델을 안정적으로 QLoRA/SFT하는 것은 완전히 다른 문제다. 추론은 메모리만 맞으면 어떻게든 돌아가는 경우가 많지만, 학습은 optimizer, gradient, checkpoint, 데이터 로딩, mixed precision, 커널 호환성까지 같이 본다.
그러니까 “128GB 통합 메모리니까 70B 파인튜닝 가능?”이라는 질문에는 이렇게 답하는 편이 낫다.
가능할 수 있다. 하지만 어떤 방식의 파인튜닝인지, 어떤 precision인지, 어떤 framework인지, 얼마나 빠르게 반복할 수 있는지가 더 중요하다.
4. Mac Studio: 큰 메모리와 조용한 연구실
Mac Studio의 강점은 명확하다. 조용하고, 작고, 전기를 비교적 적게 먹고, macOS 작업환경과 잘 결합된다. Apple 공식 스펙상 2025 Mac Studio는 M4 Max에서 최대 128GB 통합 메모리, M3 Ultra에서 최대 256GB 통합 메모리를 제공한다.1
Apple Silicon에서 LLM을 다루는 대표 경로는 MLX다. mlx-lm으로 LoRA 스타일 튜닝을 돌리는 사례는 이미 꽤 쌓였다. Niklas Heidloff는 Apple MLX로 Mistral 7B를 MacBook Pro M3에서 로컬 파인튜닝한 사례를 정리했다.8
Mac Studio가 좋은 경우는 이렇다.
- 이미 macOS 중심으로 글쓰기·분석·개발을 하고 있다.
- 7B~14B 모델의 LoRA/SFT를 자주 돌리고 싶다.
- 32B급 이상 모델은 주로 추론·평가·실험용으로 쓰고 싶다.
- 조용한 개인 연구실 장비가 필요하다.
- 영상·문서·개발·AI 실험을 한 장비에서 다 하고 싶다.
하지만 약점도 분명하다. 대부분의 오픈소스 파인튜닝 레시피는 여전히 CUDA를 전제로 한다. Hugging Face 예제, Unsloth, bitsandbytes, DeepSpeed, FlashAttention, Axolotl, LLaMA Factory 등은 NVIDIA 환경에서 먼저 검증되는 경우가 많다. Mac에서는 MLX로 갈아타거나, PyTorch MPS 제약을 감수하거나, llama.cpp/Metal 중심으로 생각해야 한다.
즉 Mac Studio는 “AI 연구 전용 장비”라기보다 AI 연구도 가능한 매우 좋은 개인 워크스테이션이다. 이미 Apple 생태계 안에서 일하고 있고, 로컬 데이터 보안과 개인 생산성이 중요하다면 매력적이다. 하지만 논문 재현이 최우선이면 CUDA 없음이 계속 걸린다.
5. DGX Spark: CUDA 재현성을 사는 장비
DGX Spark는 방향이 다르다. NVIDIA는 이 장비를 local AI development, deployment, fine-tuning을 위한 데스크톱 AI 시스템으로 포지셔닝한다. 공식 문서에는 PyTorch, TRT-LLM 등 AI 프레임워크 지원과 대형 모델 fine-tuning 용도가 명시되어 있다.2
스펙도 연구용 냄새가 강하다.
- GB10 Grace Blackwell
- 128GB LPDDR5x coherent unified memory
- 273GB/s memory bandwidth
- FP4 기준 최대 1 PFLOP
- 단일 장비에서 최대 200B 모델 개발·테스트, 두 대 연결 시 405B 모델 작업 가능하다는 NVIDIA 설명9
- NVIDIA Marketplace 기준 $4,69910
- 컴퓨존 국내 판매가는 Dell Pro Max GB10 128GB/4TB/AS 3Y 기준 약 935만 원, HP ZGX Nano G1N 128GB/4TB 혜택가 기준 약 912.5만 원45
가장 큰 장점은 CUDA다. NVIDIA는 DGX Spark용 PyTorch fine-tuning playbook을 제공하고, 1B~70B 모델의 PEFT/SFT 환경을 안내한다.11 LLaMA Factory playbook도 제공한다.12
이건 중요하다. 연구에서 장비를 산다는 것은 FLOPS를 사는 일이 아니라, 남들이 올린 코드가 덜 깨지는 환경을 사는 일이기도 하다. CUDA는 그 점에서 여전히 압도적이다. 어떤 논문 코드를 실행할 때 README가 암묵적으로 “NVIDIA GPU가 있다”고 가정하는 경우가 너무 많다.
DGX Spark가 좋은 경우는 이렇다.
- Hugging Face/PyTorch/CUDA 레시피를 최대한 그대로 재현하고 싶다.
- QLoRA, LoRA, SFT, LLaMA Factory, PEFT 실험을 자주 한다.
- 연구실 또는 팀에서 공용 장비처럼 쓰고 싶다.
- 데이터가 민감해서 클라우드 GPU에 올리기 어렵다.
- 장비 가격보다 실험 재현성과 시간 절약이 더 중요하다.
단점은 가격과 메모리다. 128GB는 큰 용량이지만 Mac Studio M3 Ultra의 256GB 구성과 비교하면 용량 여유는 작다. 국내 구매가도 컴퓨존 기준 900만 원대라 개인 연구자가 가볍게 들이기에는 부담이 크다. 또 FP4/Tensor Core 성능은 매력적이지만, 실제 파인튜닝에서는 모델·프레임워크·precision·커널 지원 여부에 따라 체감이 달라진다. 그래도 “파인튜닝 전용 로컬 장비”라는 관점에서는 가장 정석적인 선택이다.
6. Ryzen AI Max+ 395: 가성비와 불확실성의 조합
AMD Ryzen AI Max+ 395 계열은 흥미롭다. AMD 공식 스펙 기준 16코어 Zen 5, 32스레드, Radeon 8060S, 최대 128GB LPDDR5x-8000, 총 126 TOPS, NPU 50 TOPS를 제공한다.3
Framework Desktop은 Ryzen AI Max+ 395 128GB 구성을 제공하며, Framework는 이 장비가 Llama 70B 같은 모델을 책상 위에서 돌릴 수 있다고 홍보한다.13 Framework 커뮤니티 글은 상위 128GB 구성이 $1,999부터라고 설명했고, 현재 Framework Mainboard 페이지에서는 Ryzen AI Max+ 395 128GB 보드가 $3,149로 표시된다.1415 SKU와 시점에 따라 가격 표기가 달라질 수 있으니, 실제 구매 시점에는 본체 구성가와 보드 가격을 따로 확인해야 한다.
국내에서는 컴퓨존 기준 HP Z2 Mini G1a AI Max+ 395 계열이 확인된다. 128GB/1TB 기본상품은 약 455만 원으로 표시됐지만 품절 상태였고, 128GB/2TB 구성은 약 642.7만 원, 128GB/4TB 구성은 약 729.5만 원 수준이었다.65 즉 “싸다”기보다는 DGX Spark 계열보다 낮은 가격으로 128GB급 로컬 AI 장비에 접근할 수 있다는 쪽에 가깝다.
AMD 쪽 장점은 명확하다.
- 128GB 통합 메모리급 장비를 비교적 낮은 가격대에서 접근 가능
- Linux/Windows 선택 가능
- PC 생태계 부품, 스토리지, 케이스, 네트워크 선택지가 넓음
- Framework처럼 수리·확장 철학이 강한 제품군도 있음
AMD도 Ryzen AI Max+ 395 기반 Framework Desktop 여러 대를 묶어 대형 모델을 로컬에서 돌리는 사례를 공개했다. AMD 개발자 글은 4대의 Framework Desktop 128GB 구성을 사용해 llama.cpp RPC와 ROCm으로 1조 파라미터급 GGUF 모델을 분산 추론하는 절차를 설명한다.16
다만 여기서도 구분이 필요하다. AMD 계열은 로컬 추론과 실험용 가성비가 매우 매력적이다. 하지만 파인튜닝, 특히 논문 코드 재현에서는 ROCm 드라이버, 라이브러리 버전, 특정 GPU 아키텍처 지원, 커널 호환성 변수가 남는다. CUDA 환경에서는 “검색하면 답이 나오는 문제”가 ROCm에서는 “직접 삽질해야 하는 문제”가 될 때가 있다.
AMD 계열이 좋은 경우는 이렇다.
- 예산이 제한되어 있고 128GB 메모리급 로컬 AI 장비가 필요하다.
- Linux 기반으로 직접 환경을 맞출 수 있다.
- 추론, RAG, 로컬 에이전트, 가벼운 LoRA 실험이 주 목적이다.
- 장비를 여러 대로 늘려 분산 추론 실험을 해보고 싶다.
- CUDA 논문 재현보다 비용 대비 실험량이 중요하다.
반대로 “그냥 논문 코드 받아서 빨리 돌리고 싶다”면 AMD는 아직 가장 편한 선택은 아니다.
7. 구매 의사결정 지도
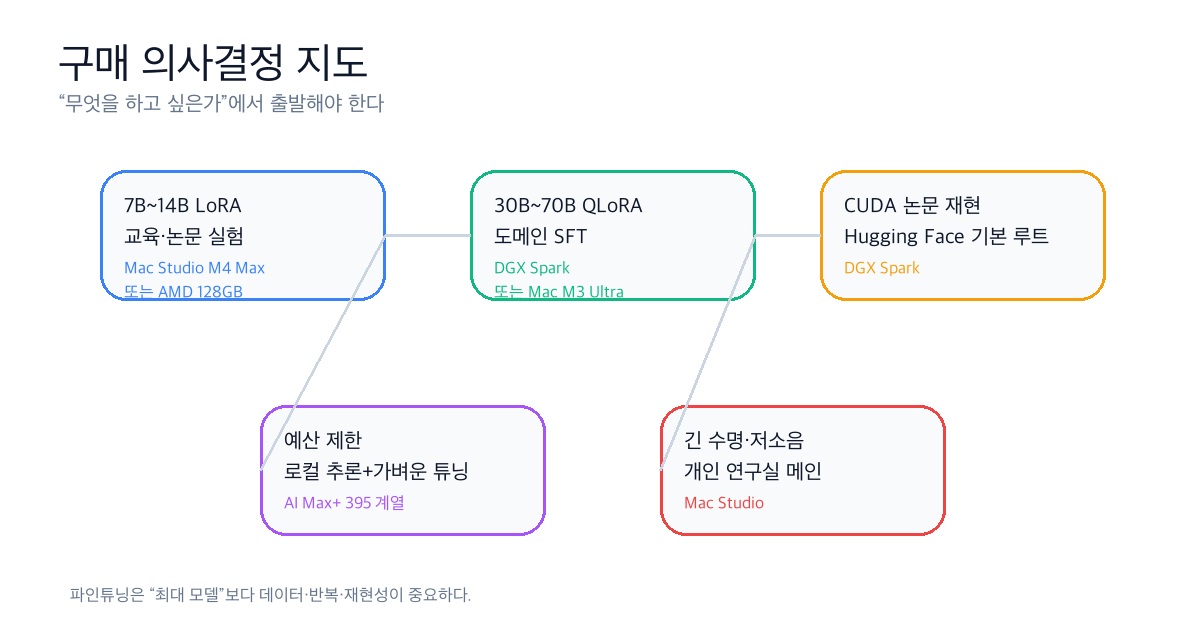
내 기준으로는 이렇게 정리할 수 있다.
| 목적 | 추천 |
|---|---|
| 7B~14B LoRA, 데이터셋 실험, 글쓰기·분석 병행 | Mac Studio M4 Max 128GB 또는 Ryzen AI Max+ 395 128GB |
| 30B~70B QLoRA/SFT, CUDA 예제 재현 | DGX Spark |
| 큰 모델 추론, 긴 컨텍스트, 조용한 개인 연구실 | Mac Studio M3 Ultra 256GB |
| 예산 제한, 로컬 추론과 실험량 | Ryzen AI Max+ 395 계열 |
| 연구실 공용 파인튜닝 장비 | DGX Spark |
| macOS 생산성 + AI 실험 통합 | Mac Studio |
8. 내가 산다면
내 상황을 기준으로 보면 조금 복잡하다. 이미 Mac mini M4 두 대와 MacBook Pro M1 Pro 32GB/2TB를 쓰고 있다. 즉 나는 이미 Apple 작업환경에 깊게 들어와 있다. 글쓰기, 블로그, 자동화, 자료정리, 개발 루틴은 macOS에 맞춰져 있다.
그래서 내가 개인 돈으로 한 대를 산다면 첫 번째 후보는 Mac Studio M3 Ultra 256GB다. 이유는 단순하다. 나에게는 “CUDA 논문 재현”보다 “내 자료를 로컬에 두고 반복적으로 읽고, 요약하고, 재구성하고, 작은 파인튜닝을 돌리는 개인 연구실”이 더 중요하기 때문이다. 그리고 macOS 생산성까지 포함하면 장비 하나가 AI 박스가 아니라 작업실이 된다.
하지만 연구실 예산으로 공용 장비를 산다면 답이 달라진다. 그때는 DGX Spark가 더 설득력 있다. CUDA, PyTorch, Hugging Face, LLaMA Factory, NVIDIA playbook은 연구실의 삽질 시간을 줄인다. 학생이나 연구원이 코드를 가져와서 돌릴 가능성까지 생각하면 재현성이 중요하다.
반대로 예산이 빡빡하고, “한 대 가격으로 여러 사람이 로컬 추론과 가벼운 튜닝을 해보자”가 목표라면 Ryzen AI Max+ 395 계열이 가장 현실적이다. 다만 이 선택은 장비보다 사람을 탄다. Linux와 ROCm 문제를 잡아줄 사람이 있으면 가성비가 살아나고, 없으면 장비는 있는데 실험이 안 굴러가는 상황이 올 수 있다.
9. 결론: 파인튜닝 장비는 성능표가 아니라 실험 습관을 사는 것이다
연구용 AI 워크스테이션을 살 때 가장 위험한 질문은 “제일 빠른 게 뭐야?”다. 더 좋은 질문은 이것이다.
- 나는 어떤 크기의 모델을 반복적으로 다룰 것인가?
- 풀 파인튜닝인가, LoRA인가, QLoRA인가?
- 논문 코드를 그대로 재현해야 하는가?
- 내 데이터는 클라우드에 올려도 되는가?
- 장비를 관리할 사람이 있는가?
- 실패한 실험을 하루에 몇 번 다시 돌릴 수 있어야 하는가?
이 질문에 따라 답은 달라진다.
Mac Studio는 개인 연구실과 큰 통합 메모리의 장비다. DGX Spark는 CUDA 재현성과 파인튜닝 워크플로우를 사는 장비다. Ryzen AI Max+ 395는 예산 대비 로컬 AI 실험량을 늘리는 장비다.
내가 이 글에서 가장 강조하고 싶은 것은 하나다. AI 워크스테이션은 “모델을 한 번 돌리는 상자”가 아니다. 연구자의 실패를 얼마나 자주, 얼마나 조용히, 얼마나 재현 가능하게 받아주는가가 핵심이다. 파인튜닝을 한다는 것은 결국 장비 성능보다 실험 반복의 습관을 사는 일이다.
확인한 출처
-
Apple Support, “Mac Studio (2025) - Tech Specs.” https://support.apple.com/en-us/122211 ↩ ↩2
-
NVIDIA Docs, “Hardware Overview — DGX Spark User Guide.” https://docs.nvidia.com/dgx/dgx-spark/hardware.html ↩ ↩2
-
AMD, “AMD Ryzen™ AI Max+ 395.” https://www.amd.com/en/products/processors/laptop/ryzen/ai-300-series/amd-ryzen-ai-max-plus-395.html ↩ ↩2
-
컴퓨존, “[Dell] Pro Max GB10 [128GB/NVMe 4TB/AS 3Y] NVIDIA DGX SPARK 기반 AI 슈퍼컴퓨터.” 2026.07.02 확인. https://www.compuzone.co.kr/product/product_detail.htm?ProductNo=1309679 ↩ ↩2
-
컴퓨존, “HP 워크스테이션/AI 워크스테이션 상품 목록.” 2026.07.02 확인. https://m.compuzone.co.kr/product/product_list.htm?BigDivNo=1&MediumDivNo=1006&DivNo=3493 ↩ ↩2 ↩3 ↩4
-
컴퓨존, “[HP] Z2 미니 G1a AI 워크스테이션 A74WTAV 라이젠 AI MAX 395+ (128GB/1TB/Win 11 Pro/3Y).” 2026.07.02 확인. https://www.compuzone.co.kr/product/product_detail.htm?ProductNo=1261231 ↩ ↩2
-
컴퓨존, “Mac Studio” 상품 목록. 2026.07.02 확인. https://m.compuzone.co.kr/product/product_list.htm?BigDivNo=3&MediumDivNo=1445&DivNo=4580 ↩
-
Niklas Heidloff, “Fine-tuning LLMs with Apple MLX locally,” 2024.05.16. https://heidloff.net/article/apple-mlx-fine-tuning/ ↩
-
NVIDIA, “NVIDIA DGX Spark: AI Supercomputer on Your Desk.” https://www.nvidia.com/en-us/products/workstations/dgx-spark/ ↩
-
NVIDIA Marketplace, “NVIDIA DGX Spark US.” https://marketplace.nvidia.com/en-us/enterprise/personal-ai-supercomputers/dgx-spark/ ↩
-
NVIDIA Build, “Fine-tune with Pytorch DGX Spark.” https://build.nvidia.com/spark/pytorch-fine-tune -
NVIDIA Build, “LLaMA Factory DGX Spark.” https://build.nvidia.com/spark/llama-factory -
Framework, “Order a Framework Desktop with AMD Ryzen™ AI Max.” https://frame.work/desktop ↩
-
Framework Community Blog, “Introducing the Framework Desktop,” 2025.02.25. https://community.frame.work/t/introducing-the-framework-desktop/65008 ↩
-
Framework Marketplace, “Framework Desktop Mainboard (AMD Ryzen™ AI Max 300 Series).” https://frame.work/products/framework-desktop-mainboard-amd-ryzen-ai-max-300-series?v=FRAFMK0006 ↩
-
AMD Developer, “Trillion-Parameter LLM on an AMD Ryzen™ AI Max+ Cluster,” 2026.02.25. https://www.amd.com/en/developer/resources/technical-articles/2026/how-to-run-a-one-trillion-parameter-llm-locally-an-amd.html ↩